


“3D Bar Graph Meeting”, (c) Scott Maxwell
The term “jargon” has complicated social meanings. Jargon primarily refers to specialized language used by a specific group of individuals; conversely, this means individuals outside of the in-crowd don’t know what the heck is being talked about when jargon starts to be tossed around. Secondary dictionary definitions attribute vaguely morally-loaded values on the term, as per dictionary.com: “unintelligible or meaningless talk or writing; gibberish”, “language that is characterized by uncommon or pretentious vocabulary and convoluted syntax and is often vague in meaning”. These negative connotations suggest people don’t like or trust jargon, presumably because of its ability to exclude. But, we have a productive option: to find out what the jargon being used actually means.
In the last couple of years, after having already invaded the sports, business, and investing industries–among others–the term “analytics” has entered the jargon of the legal researching world. Next generation interfaces almost universally boast about incorporating analytics, but why would this be beneficial? In the world of legal research, what does the term actually mean?
In our field, analytics means compiling and crunching big data in order to achieve accurate, predictive results.
Legal research, from a macro view, has always been an exercise in attempting to use past results to predict future behavior—e.g., finding precedents by reading case law. The restraints to this method of research are a lack of empiricism and a limitation in the amount of case law a person can ingest. Analytics really benefits legal researchers via its ability to quantify vast amounts of data. Rather than be limited to the case law a solitary person can ingest, analytics could potentially enable a researcher to quickly query all case law, at once. With such a vast dataset, and with data scrubbed to clean, computation-able elements, the legal predictions analytics forecasts become as accurate as they can possible be. But, this example is a hypothetical about quantifying case law, in the legal research market, what datasets are vendors quantifying, and what services are currently being offered?
MEDMAL NAVIGATOR’S CASE VALUE ASSESSMENT
MedMal Navigator’s Case Value Assessment is a perfect example of analytics. The Case Value Assessment ingests an enormous collection of settlements and verdicts from publishers including ALM, JVRA, Mealey’s, and LexisNexis Expert Research On Demand (formerly IDEX), and breaks the settlements and verdicts into discrete, quantifiable pieces. Attorneys engage in a question and answer survey with Case Value Assessment, with their answers improving the relevancy of the predicted verdict and settlement amounts. 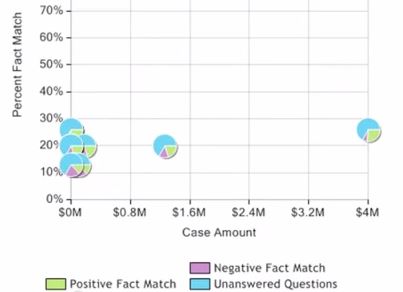 Rather than search for, and read through, a pile of verdicts and settlements, Case Value Assessment takes an enormous amount of data, breaks into discrete, computational parts, and, with a much less intense amount of effort from the attorney, produces predictive results. This is one of the primary goals of analytics: to introduce a mechanical process in order to aid decision-making, and, through this process, answer a core question like: what is the benchmark settlement amount for this specific medical product liability case?
Rather than search for, and read through, a pile of verdicts and settlements, Case Value Assessment takes an enormous amount of data, breaks into discrete, computational parts, and, with a much less intense amount of effort from the attorney, produces predictive results. This is one of the primary goals of analytics: to introduce a mechanical process in order to aid decision-making, and, through this process, answer a core question like: what is the benchmark settlement amount for this specific medical product liability case?
LEX MACHINA
Lex Machina’s award-winning software employs analytics to capture predictive data in many different avenues.  One example among the company’s many robust incorporations of analytics is its Patent Portfolio Analytics. This software digests data from Patent litigation cases, using PACER, the USPTO, and the ITC’s EDIS as its datasets. Lex Machina scrubs and organizes all of this patent litigation data, and builds algorithms on top of the data to enable users to easily query the dataset. Users are then able to obtain predictive results regarding outcomes of similar patent litigation, including specifics on appropriate settlement/agreement amounts, and even how long litigation may take in a specific jurisdiction.
One example among the company’s many robust incorporations of analytics is its Patent Portfolio Analytics. This software digests data from Patent litigation cases, using PACER, the USPTO, and the ITC’s EDIS as its datasets. Lex Machina scrubs and organizes all of this patent litigation data, and builds algorithms on top of the data to enable users to easily query the dataset. Users are then able to obtain predictive results regarding outcomes of similar patent litigation, including specifics on appropriate settlement/agreement amounts, and even how long litigation may take in a specific jurisdiction.
LEGAL SERVICES COSTS
Analytics have strongly entered the big money arena of negotiating law firm fees. ELM Solutions, Serengeti Law, and Sky Analytics all provide firms and corporations with data concerning the costs of legal services. These products use law firm invoice information as their datasets, in order to provide clients with analytically-charged law firm cost comparisons. ELM Solutions (formerly TyMetrix), for example, has ingested more than $50 billion of legal spend data into its particular dataset. The extraction of this breadth of invoice information enables users to obtain industry standard rate benchmarks; users can input a number of criteria (firm size, geographic location, practice area, industry, etc.) to arrive at even more specific cost rates. This cost rate information is invaluable for negotiating the cost of legal fees with outside firms.
CONCLUSION
Analytics have fundamentally changed other industries, and it stands to reason legal research is no different. The macro questions are, what particular datasets are conducive to and will be next in line for an analytics treatment? What new analytics-centered software are we going to encounter next? Clearly legal researchers need to have a general understanding of what analytics are, what is possible with analytics, and what new software is incorporating analytics, as this is one of the major, new avenues of legal research. At the very least, we can confidently and unabashedly pepper our conversations with the word “analytics,” and know we know what we’re talking about.

Leave a comment